Since Google published the famous GFS, MapReduce, and BigTable papers, the Internet officially ushered in the era of big data. The salient features of big data are big, big and big. This article focuses on the large volume of data, using machine learning to carry out a systematic review of the architectural problems encountered in the data processing process.
With GFS, we have the ability to accumulate a large number of data samples, such as exposure and click data of online advertisements. Naturally, the characteristics of positive and negative samples can easily obtain tens of billions and hundreds of billions of training samples in one or two months. How to store such a large sample? What kind of model can I use to learn the useful patterns in massive samples? These problems are not only engineering problems, but also worthy of every student who is doing the algorithm to think deeply.
1.1 simple model or complex model
Before the concept of deep learning was put forward, there were not many tools that the algorithm engineers could use at hand. There were several models and algorithms that were relatively fixed and relatively fixed in terms of LR, SVM, and perceptron. At that time, a practical problem was solved. More work for engineers is mainly in feature engineering. The feature engineering itself does not have a systematic guiding theory (at least there is no book that introduces the feature engineering in the system), so many times the feature construction techniques appear eccentric, whether it is useful or not depends on the problem itself, data samples, models and luck. .
At the time of feature engineering as the main work content of the algorithm engineer, most of the attempts to construct new features can not work in the actual work. As far as I know, the success rate of several large domestic companies in feature construction will generally not exceed 20% in the later period. That is to say, 80% of the new structural features often have no positive improvement effect. If you give this method a name, it is probably a simple model + complex features; the simple model says that algorithms such as LR and SVM are not serviced by themselves, and the parameters and expression capabilities basically exhibit a linear relationship and are easy to understand. Complex features refer to features that may be useful and potentially useless in feature engineering. They may be constructed in a variety of tricks, such as window sliding, discretization, and normalization. Chemistry, square root, square, Cartesian product, multi-Cartesian product, etc.; by the way, because the feature engineering itself does not have a special systematic theory and summary, so the first-time students want to construct features need to read more paper, In particular, the paper of the same or similar scene as the business scene, from which to learn the author's analysis, the method of understanding the data and the corresponding technical features of the structure; over time, is expected to form their own knowledge system.
After the concept of deep learning was proposed, it was found that deep neural networks can perform a certain degree of representation learning (representaTIon learning). For example, in the field of images, the method of extracting image features through CNN and classifying them on this basis breaks the previous algorithm. The ceiling is broken by a huge gap. This brings new ideas to all algorithm engineers. Since deep learning itself has the ability to extract features, why bother to do artificial feature design?
Although deep learning relieves the pressure of feature engineering to a certain extent, here we must emphasize two points: 1. Mitigation does not mean complete resolution. In addition to the specific field of image, in the field of personalized recommendation, deep learning has not yet been fully realized. Absolute advantage; the reason may be the inherent structure of the data itself, so that in other areas, there is no perfect CP like image +CNN. 2. Deep learning brings about complex and unexplained problems in the model while mitigating feature engineering. Algorithm engineers have to spend a lot of thought to improve the performance of the network structure design. To sum up, the simple features represented by deep learning + complex models are another way to solve practical problems.
It is difficult to determine whether the two modes are better or worse. Taking the click rate prediction as an example, in the field of computing advertising, the massive feature +LR is often the mainstream. According to the VC dimension theory, the expression ability of LR is proportional to the number of features, so massive The feature also fully enables LR to have sufficient descriptive capabilities. In the field of personalized recommendation, deep learning has just sprouted. At present, google play adopts the structure of WDL [1], and youtube adopts the structure of dual DNN [2].
Regardless of the mode, when the model is large enough, there will be cases where the model parameters cannot be stored by one machine. For example, the LR corresponding to the tens of billions of features has dozens of Gs, which is difficult to store on many single machines. Large-scale neural networks are more complicated, not only difficult to store in a single machine, but also between parameters and parameters. Logical strong dependence; to train large-scale models, it is necessary to borrow the techniques of distributed systems. This paper mainly summarizes some ideas in this aspect.
1.2 Data Parallel vs Model Parallel
Data parallelism and model parallelism are the basic concepts for understanding large-scale machine learning frameworks. The reason for this is not to go deep into it. The first time I saw it in the blog of Jeff Dean, I was in a hurry and thought I understood. Many years later, when I started to investigate this issue again, I remembered the lessons of the elders. Young people, or the drawings, Tucson broke. If you have ignored this concept as I did, I will not review it today.
These two concepts in [3] Mu Shuai once gave a very intuitive and classic explanation, but unfortunately do not know why, when I want to quote, I found that it has been deleted. I will briefly introduce this metaphor here: If you want to repair two buildings, there is an engineering team, how to operate? The first option is to divide the people into two groups, respectively, to build the building, and to renovate it; the second method is to set up a group of people to build a building, the first building is covered, the other is the first building, then the first The group continued to cover the second building. After the change, the renovation team will decorate the second building. At first glance, the second method seems to have a low degree of parallelism, but the first solution requires each engineer to have both "covering" and "decoration" capabilities, while the second option only requires everyone to own it. One ability is fine. The first scenario is similar to data parallelism, and the second scenario reveals the essence of model parallelism.
Data parallelism is relatively simple to understand. When there are many samples, in order to use all the samples to train the model, we may distribute the data to different machines, and then each machine will iterate the model parameters, as shown in the following figure.
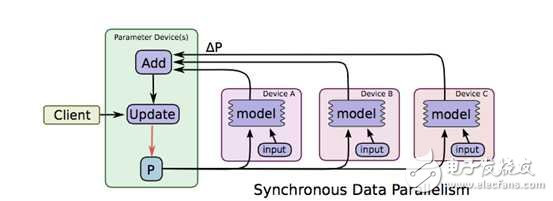
The picture is taken from TensorFlow's paper [4], where ABC represents three different machines with different samples stored, model P calculates the corresponding increments on each machine, and then summarizes them on the machine where the parameters are stored. Update, this is data parallelism. Ignore synchronous, this is the concept related to the synchronization mechanism, which will be introduced in the third section.
The concept of data parallelism is simple and does not depend on a specific model, so the data parallelism can be used as a basic function of the framework and works for all algorithms. In contrast, model parallelism has dependencies between parameters (in fact, data parallel parameter updates may also depend on all parameters, but the difference is that they are often dependent on the full number of parameters of the previous iteration. Model parallelism is often the same iteration. There is a strong dependence between the parameters within the parameters. For example, the parameters between different layers of the DNN network are dependent on the BP algorithm. It is impossible to directly classify the model parameters and destroy the dependencies, so the model parallelism is not only To slice the model, you need a scheduler to control the dependencies between the parameters. The dependencies of each model are often different, so the model parallel scheduler varies from model to model and is more difficult to be completely generic. Regarding this issue, CMU's Erix Xing is introduced in [5], and you can refer to it for your interest.
The model parallel problem definition can refer to the brother-in-law [6], this paper is also a summary of the predecessor of tensorflow, in which
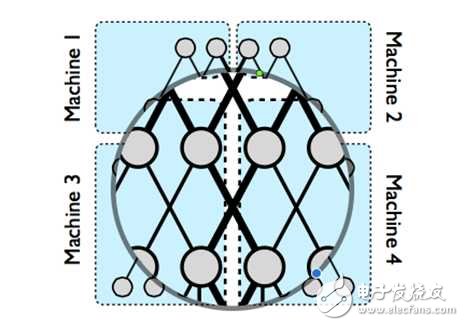
Explain the physical picture of the model parallel. When a large neural network can't be stored on one machine, we can cut the network to different machines, but in order to maintain the dependence between different parameter fragments, the picture is thick black. The part of the line needs to be concurrently controlled between different machines; the internal parameters of the same machine depend on the fine black line on the way to complete the control in the machine.
How to control the black line part effectively? As shown below
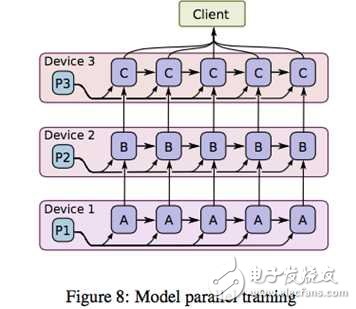
After splitting the model into different machines, we flow the parameters and samples together between different machines. In the figure, ABC represents the parameters of different parts of the model; suppose C depends on B, B depends on A, and an iteration of A is obtained on machine 1. After that, A and the necessary sample information are transmitted to machine 2 together, machine 2 is updated according to A and sample to P2, and so on; when machine 2 calculates B, machine 1 can expand the calculation of the second iteration of A. . Students who understand the CPU pipeline operation must be familiar with it. Yes, model parallelism is achieved through data pipelines. Think about the second option of the building, you can understand the essence of model parallelism.
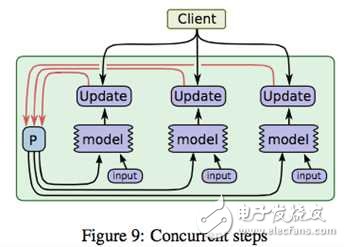
The above figure is a schematic diagram of the scheduler that relies on the control model parameters. In the actual framework, DAG (Directed Acyclic Graph) scheduling technology is generally used to implement similar functions. It has not been studied in depth, and there is an opportunity to add further explanations in the future.
It is important to understand that data parallelism and model parallelism are important to the understanding of the subsequent parameter server, but let me start with a brief introduction to some background information of the parallel computing framework.
2. Parallel algorithm evolution2.1 MapReduce route
Inspired by functional programming, Google released the distributed computing method of MapReduce [7]; by dividing the task into multiple overlapping Map+Reduce tasks, the complex computing tasks are completed.
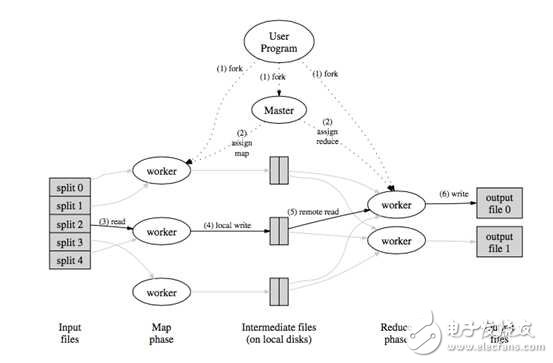
There are two main problems with MapReduce. One is that the semantics of primitives are too low-level, and they are used directly to write complex algorithms. The amount of development is relatively large. Another problem is that data is transferred by disk, and performance cannot keep up with business needs.
In order to solve the two problems of MapReduce, Matei proposed a new data structure RDD in [8] and built the Spark framework. The Spark framework encapsulates the DAG scheduler on top of the MR semantics, greatly reducing the threshold for algorithm use. Spark can be said to be a representative of large-scale machine learning for a long time. After the parameter server of Mu Shuai further developed the field of large-scale machine learning, spark revealed a little deficiency. As shown below
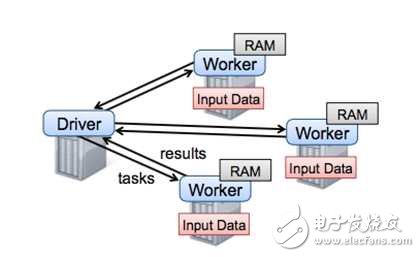
As can be seen from the figure, the spark framework takes the Driver as the core, the task scheduling and parameter aggregation are all in the driver, and the driver is a stand-alone structure, so the bottleneck of the spark is very obvious, just in the Driver here. When the size of the model is too large for a machine to survive, Spark will not function properly. So from today's point of view, Spark can only be called a medium-scale machine learning framework. Spoiler, the company's open source Angel extended Spark to a higher level by modifying the underlying protocol of Driver. This section will be described in more detail later.
MapReduce is not only a framework, but also an idea. Google's groundbreaking work has found a viable direction for big data analysis. Today, it is still out of date. It just gradually sinks from the business layer to the lower level of the underlying semantics.
2.2 MPI Technology
Mu Shuai gave a brief introduction to the prospect of MPI in [9]; unlike Spark, MPI is a system communication API similar to socket, which only supports functions such as message broadcasting. Because the MPI research is not in-depth, here is a brief introduction to the advantages and disadvantages; the advantages are system-level support, performance levers; disadvantages are also more, one is the same as MR because primitives are too low-level, using MPI to write algorithms, often code bigger. On the other hand, it is an MPI-based cluster. If a task fails, it is often necessary to restart the entire cluster, and the success rate of the MPI cluster is not high. Ali gave the following picture in [10]:
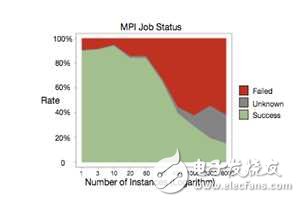
As can be seen from the figure, the probability of failure of MPI operations is close to 50%. MPI is not completely unsatisfactory. As Mu Shuai said, there are still scenes in the super-computing cluster. For the industry to rely on cloud computing, relying on commodity computers, it is not cost-effective. Of course, if in the framework of the parameter server, the use of MPI for a single set of workers is not a good attempt, [10] the Kun Peng system is officially designed.
3. Parameter server evolution3.1 Historical evolution
Mu Shuai divides the history of the parameter server into three stages in [12]. The first generation of parameter servers sprouted in Mussian's mentor Smola [11], as shown below:
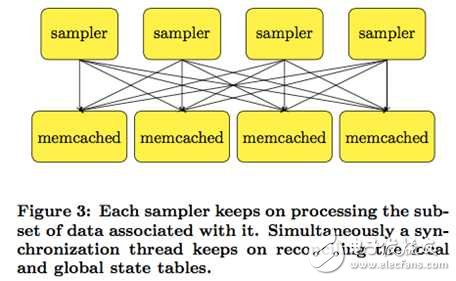
In this work, only memcached is introduced to store key-value data, and different processing processes process it in parallel. There is a similar idea in [13]. The second-generation parameter server is called applicaTIon-specific parameter server, which is mainly developed for specific applications. The most typical representative should be the predecessor of tensorflow [6].
The third-generation parameter server, which is the general parameter server framework, was formally proposed by Baidu Marshal Li Mu. Unlike the previous two generations, the third-generation parameter server was designed to be positioned as a general-purpose large-scale machine learning framework. . To get rid of the constraints of specific applications and algorithms, to make a general large-scale machine learning framework, we must first define the function of the framework; the so-called framework is often a lot of repeated, trivial, once done, do not want to come back to the second The dirty and tired work is done in a good and elegant package, so that people who use the framework can focus on their own core logic. What are the functions of the third-generation parameter server? Mu Shuai summed up these points, I copied as follows:
1) Efficient network communication: Because both the model and the sample are very large, efficient support for network communication and highly equipped network equipment are indispensable for large-scale machine learning systems;
2) Flexible consistency model: Different consistency models are tradeoff between the convergence speed of the model and the amount of cluster calculation; to understand this concept, we need to do some analysis on the evaluation of the model performance, and then leave it to the next section for further introduction.
3) Flexibility is scalable: obvious
4) Disaster tolerance: When large-scale clusters collaborate on computing tasks, it is very common to have Straggler or machine faults. Therefore, the system design itself must consider the response; when there is no fault, it may also be due to the timeliness of the task. Change the machine configuration of the cluster at any time. This also requires the framework to be able to hot swap the machine without affecting the task.
5) Ease of use: For engineers who use algorithms for algorithm tuning, it is clear that a difficult framework is not viable.
Before introducing the main technologies of the third-generation parameter server, let's look at the evolution of the large-scale machine learning framework from another perspective.
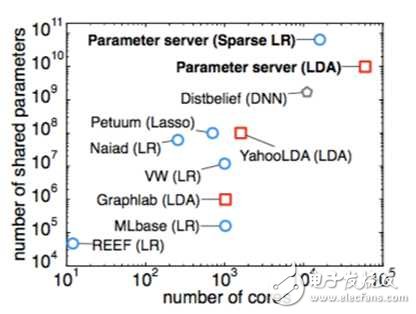
As you can see from this figure, before the parameter server came out, people have done many parallel experiments, but often only for a specific algorithm or a specific field, such as YahooLDA for the LDA algorithm. When the model parameters break through one billion, it can be seen that the parameter server is unified and there is no rival.
First, let's look at the basic architecture of the third generation of parameter servers.
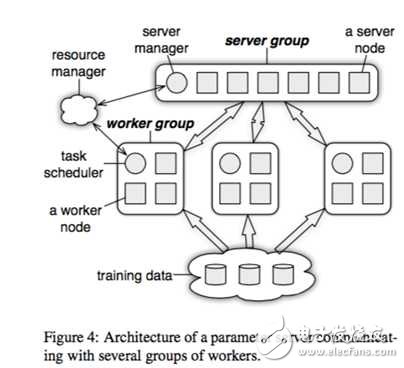
The resource manager in the above figure can be put first, because this part of the actual system is often reused with existing resource management systems, such as yarn or mesos; the training data underneath is undoubtedly required to support the distributed file system like GFS. The rest is the core components of the parameter server.
The figure draws a server group and three worker groups; the actual application is often similar, the server group uses one, and the worker group is configured on demand; the server manager is the management node in the server group, generally there is no logic, only When there is a server node to join or exit, make some adjustments to maintain a consistent hash.
The task schedule in the worker group is a simple task coordinator. When a specific task runs, the task schedule is responsible for informing each worker to load its corresponding data, and then pulling a parameter fragment to be updated on the server node. The local data sample is used to calculate the change amount corresponding to the parameter fragment, and then synchronized to the server node; after receiving the update of all the workers corresponding to the parameter fragment responsible for the local machine, the server node performs an update on the parameter fragment.
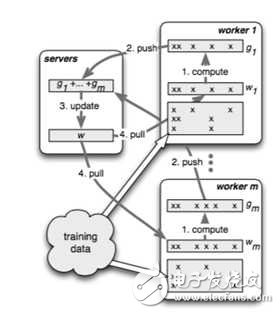
As shown in the figure, when different workers are simultaneously operating in parallel, the progress of different workers may be different due to external factors such as network and machine configuration. How to control the synchronization mechanism of workers is an important issue. See the decomposition in the next section for details.
Large Infrared Touch Frame (Splicing)
The splicing touch frame is an important part of the touch splicing screen system. Compared with other media propaganda carriers, the touch splicing screen reflects the extensiveness, intuitiveness, and fun of human-computer interaction and presentation, and has a strong visual impact. It has made a big step forward in the development of the touch industry. It is also a promoter of super-sized display integrated touch. The large-sized spliced touch TV display wall has involved schools, shopping malls, banks, digital exhibition halls, corporate exhibition halls, and government Institutions and military command can be equipped with digital content, interactive games, animation, 3D, VR, interactive audio and video, etc. It is an indispensable and effective application device for today's interactive large-screen demonstrations.
pictures show






Large Infrared Touch Frame,Large Splicing Infrared Touch Frame,Ir Multi Touch Frame,Led Touch Screen TV Wall,Large-size Infrared Touch Screen,LCD Touch Screen TV Wall
ShenZhen GreenTouch Technology Co.,Ltd , https://www.bbstouch.com