The Observer coprocessor is typically triggered before or after a specific event, such as a Get or Put operation, functioning similarly to a trigger in RDBMS. The Endpoint coprocessor is analogous to stored procedures in RDBMS because it allows users to perform custom calculations directly on the RegionServer instead of on the client side.
1 Introduction to CoprocessorWhen you need to count data in HBase, such as finding the maximum value of a field, counting records that meet certain conditions, analyzing record characteristics, or classifying them based on those features, the traditional approach involves scanning the entire table and performing statistical processing on the client side. This method can lead to significant overhead, including high network bandwidth usage and increased RPC pressure.
HBase, as a columnar database, has often faced criticism for its inability to easily create secondary indexes and for difficulties in performing aggregations, counts, and sorting. In earlier versions (like 0.92), calculating the total number of rows required using the Counter method or running a MapReduce job. While HBase integrates MapReduce for distributed data processing, many simple aggregation tasks could benefit from executing the calculation directly on the server side, reducing network overhead and improving performance. Hence, HBase introduced coprocessors after version 0.92, enabling features like easy secondary index creation, complex filters, and access control.
In simple terms, a coprocessor is a mechanism that allows users to execute part of their logic on the data storage side, which is the HBase server. It enables users to run their own code directly on the HBase server.
2 Classification of CoprocessorsThere are two types of coprocessors: system coprocessors, which apply globally to all tables on a RegionServer, and table coprocessors, which are specified for individual tables. The coprocessor framework offers two different plugin interfaces to enhance flexibility. One is the Observer, similar to triggers in relational databases. The other is the Endpoint, akin to stored procedures.
The Observer design allows users to insert their code into the coprocessor framework, enabling specific events to trigger callback methods executed by HBase core code. The coprocessor framework handles all callback details, while the coprocessor itself only needs to add or modify functionality.
The Endpoint is an interface for dynamic RPC plugins. Its implementation is installed on the server side, allowing it to be invoked via HBase RPC. The client library provides a convenient way to call these dynamic interfaces, enabling remote execution of the code and returning results to the client. Users can combine these powerful interfaces to extend HBase's capabilities.
3 Use of Protocol BufferSince the following Endpoint encoding example uses Google's mixed-language data standard Protocol Buffer, let's first look at the tools commonly used in RPC systems.
3.1 Introduction to Protocol BufferProtocol Buffer is a lightweight and efficient structured data format suitable for serialization and ideal for data storage or RPC data exchange. It supports language and platform independence and is scalable for communication protocols, data storage, and more. APIs are available in C++, Java, and Python.
Why use Protocol Buffer? Consider a common scenario in development where your client program is written in Java and runs on various platforms like Linux, Windows, or Android, while your server program is usually developed on Linux using C++. There are several ways to design a message format when communicating between the two programs:
1. Directly passing byte-aligned structures in C/C++ is convenient for C/C++ programs but cumbersome for Java developers. They must store received data in ByteBuffer and read each field according to the agreed byte order, then assign values to domain variables, making the process tedious.
2. Using the SOAP protocol (WebService) as the message format results in text-based messages with large XML descriptions, increasing network IO burden and reducing parsing performance due to XML complexity.
Protocol Buffer effectively solves these issues and ensures compatibility between new and old versions of the same message.
3.2 Installing Protocol BufferAfter downloading protobuf-2.6.1.tar.gz from https://developers.google.com/protocol-buffers/docs/downloads, extract it to the specified directory:
$ tar -xvf protobuf-2.6.1.tar.gz -C app/
Remove the zip file:
$ rm protobuf-2.6.1.tar.gz
Install the C++ compiler package:
$ sudo apt-get install g++
Compile and install Protocol Buffer:
$ cd app/protobuf-2.6.1/
$ ./configure
$ make
$ make check
$ sudo make install
Add to lib:
$ vim ~/.bashrc
Export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/lib
$ source ~/.bashrc
Verify installation:
$ protoc --version
3.3 Writing proto filesFirst, write a proto file defining the structured data to be processed. Proto files resemble data definitions in Java or C. Here is an example of the endpoint.proto file defining the RPC interface:
option java_package = "com.hbase.demo.endpoint"; // Specify the package name of the generated Java code
option java_outer_classname = "Sum"; // Specify the external class name to generate Java code
option java_generic_services = true; // Generate abstract service code based on service definition
option optimize_for = SPEED; // Specify the optimization level
message SumRequest {
required string family = 1; // column family
required string column = 2; // column name
}
message SumResponse {
required int64 sum = 1 [default = 0]; // summation result
}
service SumService {
// Get the summation result
rpc getSum(SumRequest)
returns (SumResponse);
}
3.4 Compiling proto filesCompile the proto file to generate Java code:
$ protoc endpoint.proto --java_out=.
The generated file Sum.java is shown below:
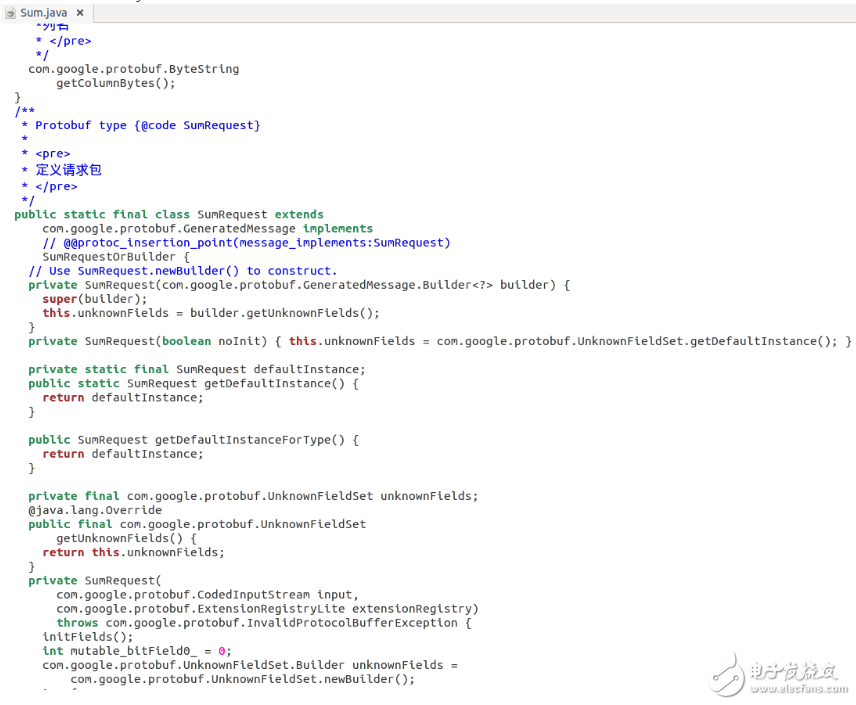
Business logic such as summation and sorting can be placed on the server side. After the server completes the calculation, the result is sent to the client, reducing the amount of data transmitted. The following example will generate an RPC service on the HBase server side, where the server sums the values of a specified column in a table and returns the result to the client. The client calls the RPC service and outputs the response result.
4.1 Server CodeImport the RPC interface file Sum.java generated by Protocol Buffer into the project, then create a new class SumEndPoint in the project to write the server code:
[java] view plain copypackage com.hbase.demo.endpoint;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.Coprocessor;
import org.apache.hadoop.hbase.CoprocessorEnvironment;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.coprocessor.CoprocessorException;
import org.apache.hadoop.hbase.coprocessor.CoprocessorService;
import org.apache.hadoop.hbase.coprocessor.RegionCoprocessorEnvironment;
import org.apache.hadoop.hbase.protobuf.ResponseConverter;
import org.apache.hadoop.hbase.regionserver.InternalScanner;
import org.apache.hadoop.hbase.util.Bytes;
import com.google.protobuf.RpcCallback;
import com.google.protobuf.RpcController;
import com.google.protobuf.Service;
import com.hbase.demo.endpoint.Sum.SumRequest;
import com.hbase.demo.endpoint.Sum.SumResponse;
import com.hbase.demo.endpoint.Sum.SumService;
/**
* @author developer
* Description: server code for hbase coprocessor endpooint
* Function: Inherit the rpc interface generated by the protocol buffer, perform the summation operation after the server obtains the data of the specified column, and finally return the result to the client.
*/
Public class SumEndPoint extends SumService implements Coprocessor,CoprocessorService {
Private RegionCoprocessorEnvironment env; // Define the environment
@Override
Public Service getService() {
Return this;
}
@Override
Public void getSum(RpcController controller, SumRequest request, RpcCallback"SumResponse" done) {
// Define the variable
SumResponse response = null;
InternalScanner scanner = null;
// Set the scan object
Scan scan = new Scan();
scan.addFamily(Bytes.toBytes(request.getFamily()));
scan.addColumn(Bytes.toBytes(request.getFamily()), Bytes.toBytes(request.getColumn()));
// scan each region, sum after value
Try {
Scanner = env.getRegion().getScanner(scan);
List "Cell" results = new ArrayList "Cell" ();
Boolean hasMore = false;
Long sum = 0L;
Do {
hasMore = scanner.next(results);
For (Cell cell : results) {
Sum += Long.parseLong(new String(CellUtil.cloneValue(cell))));
}
results.clear();
} while (hasMore);
// Set the return result
response = SumResponse.newBuilder().setSum(sum).build();
} catch (IOException e) {
ResponseConverter.setControllerException(controller, e);
} finally {
If (scanner != null) {
Try {
scanner.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
// Return the rpc result to the client
done.run(response);
}
// method called when the coprocessor is initialized
@Override
Public void start(CoprocessorEnvironment env) throws IOException {
If (env instanceof RegionCoprocessorEnvironment) {
This.env = (RegionCoprocessorEnvironment)env;
} else {
Throw new CoprocessorException("no load region");
}
}
// method called when the coprocessor ends
@Override
Public void stop(CoprocessorEnvironment env) throws IOException {
}
}
4.2 Client CodeCreate a new class SumClient in the project as a client test program that calls the RPC service. The code is as follows:
[java] view plain copypackage com.hbase.demo.endpoint;
import java.io.IOException;
import java.util.Map;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.coprocessor.Batch;
import org.apache.hadoop.hbase.ipc.BlockingRpcCallback;
import com.google.protobuf.ServiceException;
import com.hbase.demo.endpoint.Sum.SumRequest;
import com.hbase.demo.endpoint.Sum.SumResponse;
import com.hbase.demo.endpoint.Sum.SumService;
/**
* @author developer
* Description: client code for hbase coprocessor endpooint
* Function: Get the summation result of the data of the specified column of the hbase table from the server
*/
Public class SumClient {
Public static void main(String[] args) throws ServiceException, Throwable {
Long sum = 0L;
// Configure HBse
Configuration conf = HBaseConfiguration.create();
Conf.set("hbase.zookeeper.quorum", "localhost");
Conf.set("hbase.zookeeper.property.clientPort", "2222");
// Establish a database connection
Connection conn = ConnectionFactory.createConnection(conf);
// Get the table
HTable table = (HTable) conn.getTable(TableName.valueOf("sum_table"));
// Set the request object
Final SumRequest request = SumRequest.newBuilder().setFamily("info").setColumn("score").build();
// Get the return value
Map "byte[], Long" result = table.coprocessorService(SumService.class, null, null,
New Batch.Call "SumService, Long"() {
@Override
Public Long call(SumService service) throws IOException {
BlockingRpcCallback "SumResponse" rpcCallback = new BlockingRpcCallback "SumResponse" ();
service.getSum(null, request, rpcCallback);
SumResponse response = (SumResponse) rpcCallback.get();
Return response.hasSum() ? response.getSum() : 0L;
}
});
// Iteratively add the return value
For (Long v : result.values()) {
Sum += v;
}
// result output
System.out.println("sum: †+ sum);
// close the resource
Table.close();
Conn.close();
}
}
4.3 Loading EndpointPackage the Sum and SumEndPoint classes and upload them to HDFS:
$ hadoopfs -put endpoint_sum.jar /input
Modify the HBase configuration file, add configuration:
$ vim app/hbase-1.2.0-cdh5.7.1/conf/hbase-site.xml
[html] view plain copy "property"
"name" hbase.table.sanity.checks "/name"
"value" false "/value"
"/property"
Restart HBase:
$stop-hbase.sh
$start-hbase.sh
Start the HBase shell:
$hbase shell
Create a table sum_table:
》 create'sum_table', 'info'
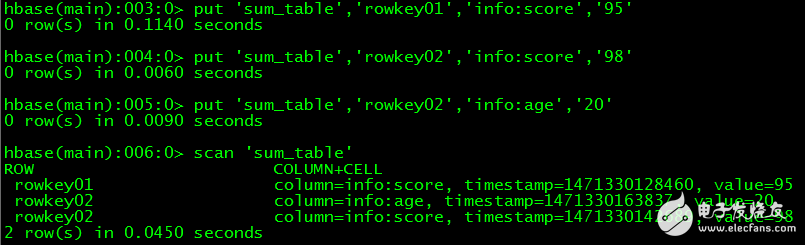
Insert test data:
》 put'sum_table', 'rowkey01', 'info:score', '95'
》 put'sum_table', 'rowkey02', 'info:score', '98'
》 put'sum_table', 'rowkey02', 'info:age', '20'
View data:
》 scan'sum_table'
Load the coprocessor:
》disable 'sum_table'
Alter'sum_table', METHOD = "'table_att', 'coprocessor' = "'hdfs://localhost:9000/input/endpoint_sum.jar|com.hbase.demo.endpoint.SumEndPoint|100'
》enable 'sum_table'

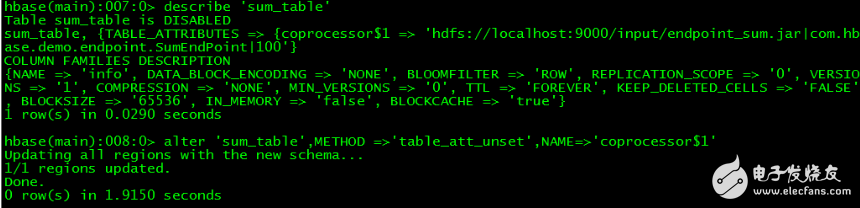
To uninstall the coprocessor, first check the coprocessor name in the table and then uninstall it by command:
》disable 'sum_table'
" describe'sum_table'
》 alter'sum_table', METHOD = "'table_att_unset', NAME="'coprocessor$1'
》 enable'sum_table'
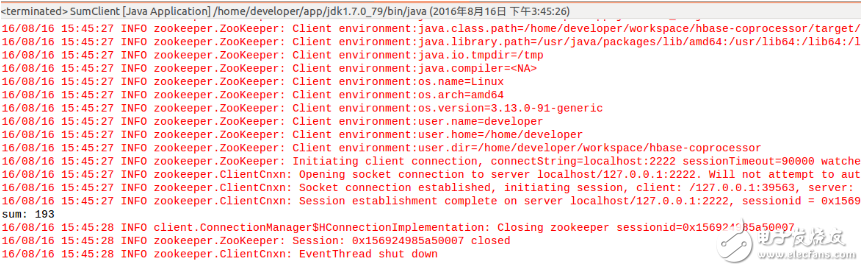
Run the client program SumClient in Eclipse, the output is 193, just in line with expectations, as shown below:
Generally, indexing a database requires a separate data structure to store the indexed data. In HBase tables, in addition to using rowkey index data, you can also create an additional index table, query the index table first, and then query the data table with the query results. The following example shows how to use the Observer coprocessor to generate a secondary index for the HBase table: the value of the column info:name in the data table ob_table is used as the rowkey of the index table index_ob_table, and the value of the column info:score in the data table ob_table is used as the index table index_ob_table column info:score value to establish a secondary index. When the user inserts data into the data table, the index table will automatically insert the secondary index, facilitating querying the business data.
5.1 CodeIn the project, create a new class PutObserver as the Observer coprocessor application logic class, the code is as follows:
[java] view plain copypackage com.hbase.demo.observer;
import java.io.IOException;
import java.util.List;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Durability;
import org.apache.hadoop.hbase.client.HTableInterface;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.coprocessor.BaseRegionObserver;
import org.apache.hadoop.hbase.coprocessor.ObserverContext;
import org.apache.hadoop.hbase.coprocessor.RegionCoprocessorEnvironment;
import org.apache.hadoop.hbase.regionserver.wal.WALEdit;
import org.apache.hadoop.hbase.util.Bytes;
/**
* @author developer
* Description: application logic code of hbase coprocessor observer
* Function: In the hbase table to which the observer is applied, all put operations will use the info:name column value of each row of data as the rowkey and info:score column values as the value.
* Write another secondary index table index_ob_table to improve query efficiency for specific fields
*/
@SuppressWarnings("deprecation")
Public class PutObserver extends BaseRegionObserver{
@Override
Public void postPut(ObserverContext "RegionCoprocessorEnvironment" e,
Put put, WALEdit edit, Durability durability) throws IOException {
// Get the secondary index table
HTableInterface table = e.getEnvironment().getTable(TableName.valueOf("index_ob_table"));
// get the value
List "Cell" cellList1 = put.get(Bytes.toBytes("info"), Bytes.toBytes("name"));
List "Cell" cellList2 = put.get(Bytes.toBytes("info"), Bytes.toBytes("score"));
// Insert data into the secondary index table
For (Cell cell1 : cellList1) {
// column info:name value as the rowkey of the secondary index table
Put indexPut = new Put(CellUtil.cloneValue(cell1));
For (Cell cell2 : cellList2) {
// column info: score value as the value of the column info:score in the secondary index table
indexPut.add(Bytes.toBytes("info"), Bytes.toBytes("score"), CellUtil.cloneValue(cell2));
}
// Data is inserted into the secondary index table
table.put(indexPut);
}
// close the resource
table.close();
}
}
5.2 Loading ObserverPackage the PutObserver class and upload it to HDFS:
$ hadoopfs -put ovserver_put.jar /input
Start the HBase shell:
$hbase shell
Create a data table ob_table:
》 create'ob_table', 'info'
Create a secondary index table ob_table:
》 create'index_ob_table', 'info'
Load the coprocessor:
》disable 'ob_table'
Alter'ob_table', METHOD = "'table_att', 'coprocessor' = "'hdfs://localhost:9000/input/observer_put.jar|com.hbase.demo.observer.PutObserver|100'
》 enable'ob_table'
View data table ob_table:
" describe'ob_table'

Write a client in
Wuxi Ark Technology Electronic Co.,Ltd. , https://www.arkledcn.com